Last Updated: October 25, 2021
The consumer goods industry has faced challenges in recent years. According to McKinsey, growth rates are down from 9.7% in 2011 to 1.2% in 2018. And the Institute of Business Forecasting suggests that the average 1-year forecast for consumer products is off by 20%. For a company with $1 billion in annual revenue, that can result in as much as $225 million in annual losses on excess inventory costs alone. In order to plan for what is coming, the past might now be completely reliable.
Most CPG companies rely on historical sales trends to predict future performance, nearly ignoring external factors that can affect demand. Technologies such as machine learning and cloud-computing provide the ability to incorporate external data to understand changes in consumer behavior, demographics, and economic headwinds that will affect performance.
Incorporating External Data and Machine Learning
External data in the context of category growth performance corresponds to the various ‘uncontrollable drivers or signals’ of demand. While organizations typically have a good understanding of how their internal sales and marketing tactics influence category performance, they often struggle to explain the unexpected, which is largely driven by external factors.
The power of machine learning lies in its ability to learn over time. Machine learning can quickly sort through decades worth of data. And when all this information is combined, Machine learning models have the potential to discern patterns and make accurate predictions about everything from shifting consumer opinions and habits, changes within the industry landscape affects upcoming weather patterns will have on demand, etc.
As the term machine learning implies, the algorithm is learning based on the information you provide. Over time with more data to train against, AI models improve accuracy and forecasts have the potential to be fined tuned to address the unique needs of the company.
5 Steps to Incorporate External Data and Machine Learning into Planning Processes
At Prevedere, we take a five-step approach to incorporating external data and applying machine learning to our customers’ planning processes.
Step 1: Business Discovery Session to Identify the Best Category
The Ideal category is one with the largest sales volume and with the best historical performance data. Ensuring there is enough historical data makes it easier to determine strong correlations with external factors.
Step 2: Run Machine Learning Analysis. After identifying the ideal category and gathering three to five years of historical data, analysis is performed using Prevedere’s Prevedere Predictive Analytics Cloud software. The machine learning-based engine rapidly analyzes over 2.5 million economic and consumer behavior data sets to identifies the most predictive indicators for the chosen category.
Step 3. Review and validate. Our data scientists and economist will review the leading indicators selected from our software. We will then meet with your team and leadership to gain a mutual understanding of why certain external variables were included, why others were discarded, and review the overall methodology used.
Step 4. Develop and Test Predictive Model(s). Using Prevedere’s software, we combine all the selected leading indicators to develop a single predictive model for the chosen category. The software will also perform numerous backtests to see if the combined leading indicators can accurately model past data. If it can accurately recreate historical performance, there is high confidence that the right mix of external factors has been chosen to predict future performance.
Step 5. Finalize and Deliver Category Demand. The last step is to review the findings with key stakeholders in the organization. Often executives are keenly interested in this methodology and results as it will greatly help them in strategic planning and financial forecasting. Since our predictive models are updated in real-time, any changes in the economy will be reflected in the category demand model immediately. We deliver these new insights through existing reporting channels and processes to improve ease-of-use. Prevedere’s economist also perform periodic review of category models – ensuring they predict the future as accurately as possible
Machine Learning and External Data at Work
The following chart is an example of machine learning and external data at work. This is the total U.S. sales volume for a leading brewing company. Traditional forecasting methods rely on internal data. So, if anything changes externally, traditional methods won’t capture it. By incorporating external data, models capture changes in the economy where traditional models do not. As the chart illustrates, too much emphasis on the traditional method was placed on seasonality and historical performance. The sales volume would have been significantly incorrect had the traditional method been used resulting in missed targets and perhaps increased inventory assumptions – maybe future markdowns required.
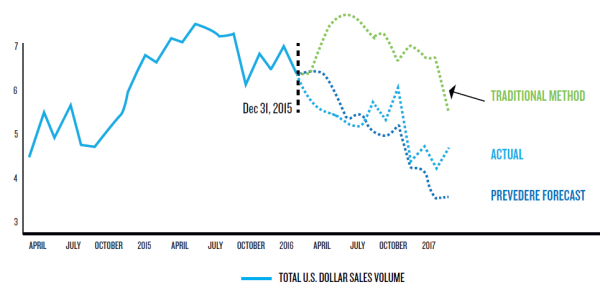
An incorrect or inaccurate forecast can have significant consequences. Failing to properly identify competition, new retail channels, or a decrease in new stores for distribution can not only hurt your sales, but they could leave you with more inventory and less income than you expected. This, in turn, can impact cash flow going forward. Increased costs, out-of-stock items, and markdowns from overstocking are also very real possibilities resulting from a poor forecast.

For more insight, watch “A Clearer View of Future Demand, Category Demand Planning with Machine Learning and External Data” now >>
